Humans use their two hands and ten fingers to do tasks every day. We can fold laundry or open bottle caps without a second thought. These activities seem simple to us, but they require constant, real-time coordination between our limbs and many joints.
Robots struggle with these contact-rich, deformable interactions. Programming every motion rule for a robot to mimic human dexterity is difficult and scales poorly.
Robot learning through human demonstration provides a solution to this problem. It allows the team to capture examples, recover the task state, retarget the motion to robot kinematics, and train a policy that acts from observation.

In this article, we’ll explore how human demonstrations are transformed into robotic policies for dexterous manipulation.
Deconstructing the Demonstration: What the Robot Actually Learns
Robot learning from a human demonstration requires converting physical data into a mathematical policy. The robot learns by feeding multiple data streams into neural networks. These networks map visual and tactile observations to specific robot actions.
Visual and Kinematic Tracking
Robots learn to track physical trajectories by observing a human demonstrator’s wrist and finger movements either through a recorded video or motion-tracking hardware. Computer vision algorithms analyze RGB images to track the human’s exact wrist pose and finger articulations.
Specifically, the system uses hand models like MANO to transform 2D pixels into a 3D hand mesh. MANO maps human pose parameters to 21 specific joint locations, providing the robot with a precise reconstruction of the human’s kinematic trajectory to mimic during dexterous manipulation.
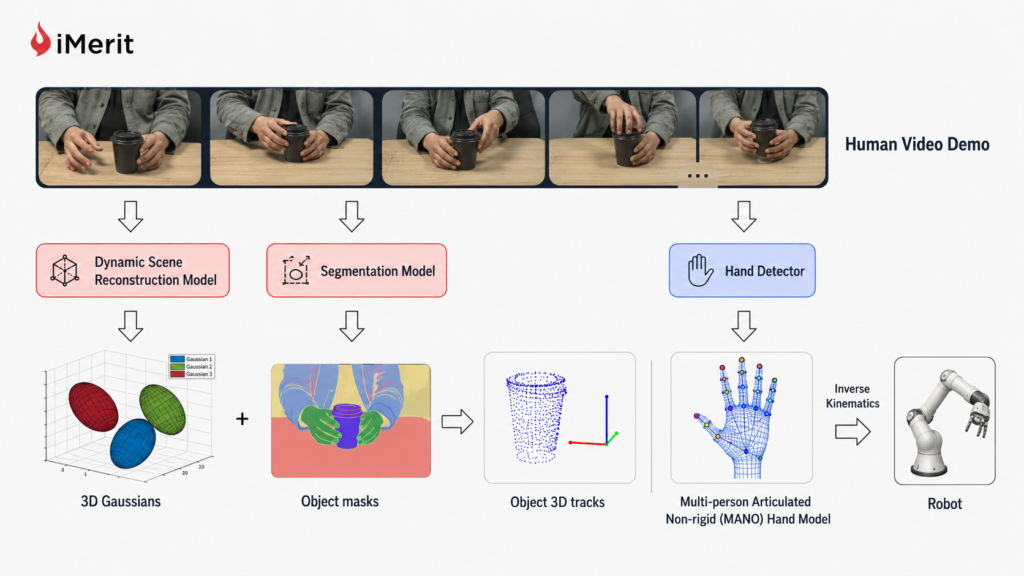
Object State and Pose Estimation
The human demonstration provides continuous visual data of the target object. As the human manipulates it, the system extracts its geometry and tracks its changing 6-Degree-of-Freedom spatial orientation.
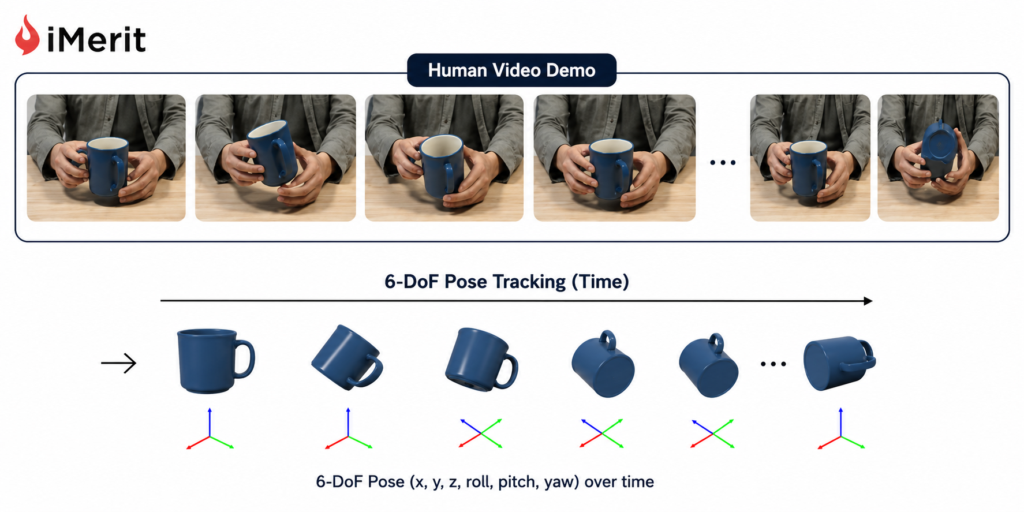
Pose estimation networks compare live observations against known 3D CAD models, giving the robot reference views to understand how the object’s state changes throughout a task.
Inferring Contact
Robots cannot learn about weight, friction, or stiffness through vision alone. They learn these physical traits through tactile feedback during the demonstration. Human demonstrators wear sensorized tactile gloves that measure their fingertip pressure and help the robot understand the exact amount of force needed to do the task.
Additionally, some robots are equipped with optical tactile sensors, like the GelSight Mini. When the sensor touches an object, an internal camera records the silicone surface’s physical deformation. Artificial intelligence algorithms analyze these deformation images and convert the visual changes into exact force measurements.
Imitation Learning: Bridging Human Skill and Robot Action
The robot uses imitation learning to convert human motion into motor commands. It trains a policy from expert behavior and removes the need to manually design complex reward functions.
There are several imitation learning algorithms, with the most common being behavioral cloning and demo-augmented policy gradient.
- Behavioral cloning treats robot policy learning as a standard supervised learning problem and maps observations to actions based strictly on the expert dataset. But it operates offline and suffers from execution errors because the policy cannot recover from unfamiliar states outside the demonstration trajectory.
- Demo Augmented Policy Gradient addresses these limitations by integrating reinforcement learning with imitation learning. It pre-trains a baseline policy using behavioral cloning, then fine-tunes it through active interaction with the environment. The reinforcement learning phase allows the robot to explore slightly outside the strict human trajectories and teaches it how to actively recover from its own errors.
While these offline methods ingest static demonstrations, interactive imitation learning takes a collaborative approach and places a human teacher actively in the loop. The robot executes the learned policy in the real physical environment. The human expert watches the execution closely. When the robot deviates from the correct path or enters an unfamiliar state, the human operator intervenes immediately.
The operator provides corrective feedback using specialized teleoperation devices such as haptic gloves to refine robot manipulation skills on the fly. The haptic glove controls the robotic hand and forces it back onto the correct geometric path.
Capturing Demonstrations: Teleoperation and Video Retargeting
Teams capture human demonstrations through datasets of recorded video or direct hardware-based teleoperation systems.
Direct Collection via Teleoperation
Teams capture real-time human hand trajectories using sensorized wearable exoskeletons and teleoperation systems. Human demonstrators wear advanced hardware to record their movements. Haptic gloves track hand configurations and provide force feedback, while mixed-reality headsets capture first-person video of task execution.
The system maps the human operator’s movements to the robot’s control system. When the human moves a finger, the teleoperation system moves the corresponding robotic finger. The system logs the joint states, the exact object poses, and the visual feeds continuously. Direct teleoperation generates clean, functional data. And the mapping between the human intention and the recorded robotic action remains perfectly aligned.

Scaling via Video Retargeting
Collecting paired human-robot data through active teleoperation requires extensive hardware setups. To bypass this bottleneck, teams use video-based motion retargeting. They utilize computer vision to extract 3D hand-object poses from readily available datasets of human manipulation videos. The retargeting pipeline then converts these extracted human hand motions into deployable robot motor commands.
Because anatomical differences exist between human and robot hands, teams use constrained optimization and inverse kinematics to translate demonstrations while preserving object interactions and contact regions.
However, raw video of human demonstrations is not actionable data on its own, as it often contains visual noise, varied lighting, and severe visual occlusions where the hand blocks the camera’s view of the object. If your team needs to capture and annotate custom high-quality human demonstrations for robot manipulation, iMerit can help you build a scalable, model-ready data pipeline.
For example, iMerit partnered with a humanoid robotics startup to process over 200 hours of first-person human demonstration video. Our domain-trained workforce transformed raw household task recordings into structured, classified training data to teach dexterous robots complex physical interactions.
Discover how this approach accelerates robot learning in our human-centered robot training case study.
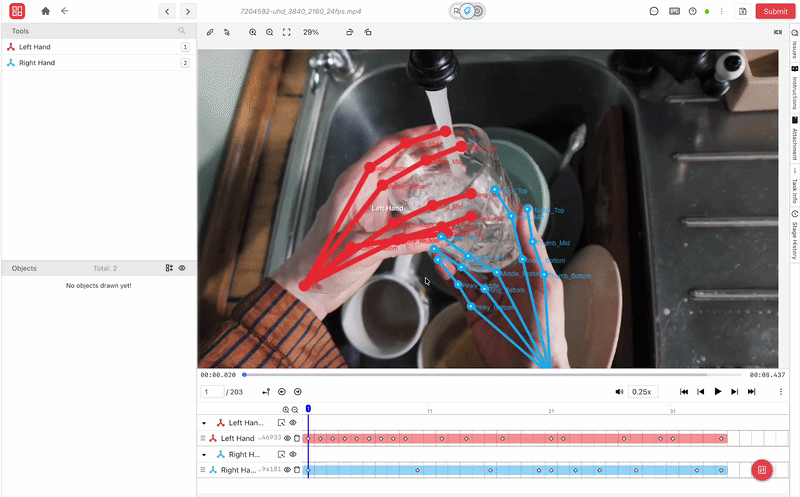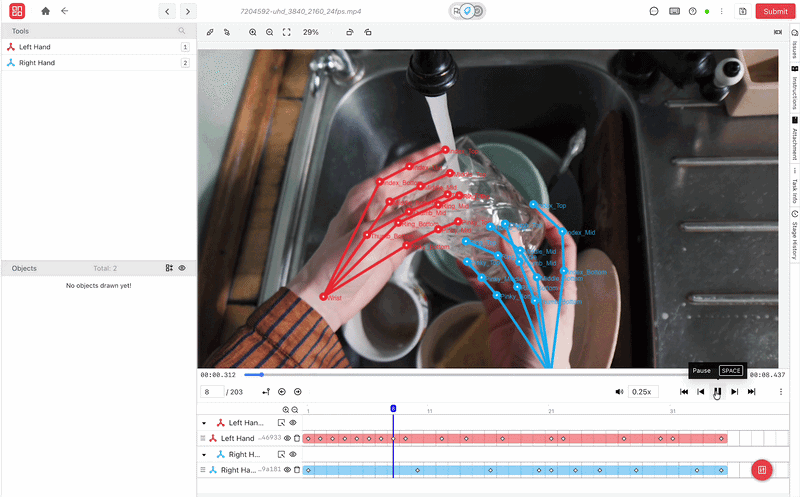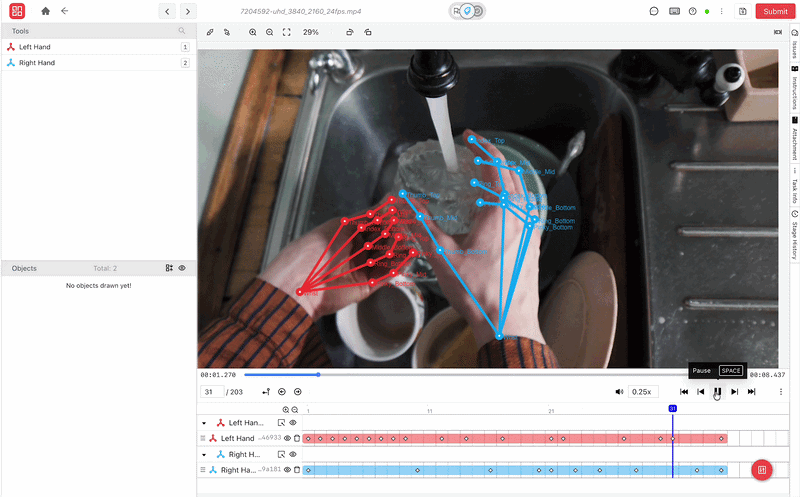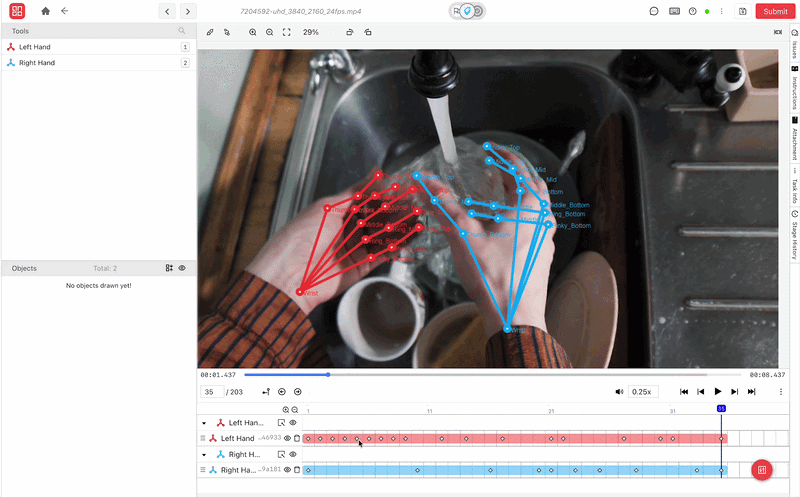
Scaling Dexterous Learning: Challenges in Real-World Deployment
Moving dexterous manipulation from the laboratory to the real-world deployment presents several scaling challenges. Including:
- The Sourcing Constraint: Scaling robot learning demands vast, diverse datasets. Manual collection of real-world demonstrations is difficult, and narrow datasets produce brittle policies. Simulation often fails to bridge the gap because it cannot perfectly replicate complex real-world friction and contact dynamics.
- The Ground Truth Requirement: Raw data requires extensive labeling and temporal segmentation to establish ground truth. High-performance models depend on synchronized streams like LiDAR and RGB, and minor sensor misalignments cause model confusion. Furthermore, 3D point clouds introduce occlusion and motion challenges for accurate annotation.
- Long-Horizon Tasks: Chaining sub-skills into multi-step behaviors introduces compounding errors. Bimanual coordination further complicates this, requiring perfect timing and collision avoidance between hands during dexterous manipulation tasks. A single timing error or slip can cause the entire long-horizon sequence to fail.
How iMerit Supports Scalable Dexterous Robot Learning
Building a scalable dexterous manipulation pipeline requires technical infrastructure and domain-specialized annotation expertise. iMerit supports enterprise robotics teams across both.
- Hand Keypoint and 6-DoF Pose Annotation: iMerit delivers precise labeling of twenty-one-joint human hand skeletons and full six-degree-of-freedom object poses across multi-view RGB-D streams. That structured data provides the ground truth needed for retargeting algorithms and reinforcement learning.
- Grasp Taxonomy Labeling: iMerit allows teams to perform structured classification of grasp strategies across object types using the Feix taxonomy. This classification helps robots build diverse skill libraries instead of relying on a single learned policy for every interaction.
- Contact Region Annotation: Experts identify exact finger-object contact zones and mask surface points on the object frame by frame. It enables robots to learn physical boundaries, normal force, and friction that vision-only tracking pipelines miss.
- Ango Hub: It helps teams process high-fidelity human demonstration data (RGB-D, LiDAR, IMU, force/torque streams, and egocentric video). Ango Hub operationalizes raw, noisy demonstrations into ground truth for imitation learning and motion retargeting through:
- End-to-End Workflow Automation and Multi-Modal Orchestration: Ango Hub lets teams design custom, no-code pipelines that ingest synchronized multi-sensor streams and route tasks intelligently across labeling, review, and QA stages. Workflows can be adjusted on the fly with AI pre-labeling, automated validation, and human-in-the-loop corrections.
- Advanced 3D and Sensor Fusion Capabilities Tailored for Manipulation Data: It supports multi-view RGB-D synchronization, 3D point cloud annotation, and sensor fusion. Features such as Merged Point Cloud aggregate spatial data across frames into a unified coordinate system. It enables precise tracking of 6-DoF object poses, 21-joint hand keypoints, contact regions, and hand-object interactions even under occlusion in long-horizon bimanual tasks.
- Expert-in-the-Loop QA: iMerit deploys a workforce trained in domain-specific robotics curricula, governed by a strict two-stage quality assurance workflow to catch microscopic geometric errors.
Conclusion
Teaching robots to perform dexterous, human-like manipulation is still a technical challenge. Using human demonstrations via advanced imitation learning, behavioral cloning, and motion retargeting, teams can accelerate robot learning. However, the effectiveness of robot models depends on the quality, accuracy, and scale of the underlying ground truth data.
To develop reliable and adaptable robotic manipulation policies, you need accurate 3D annotation and domain-expert data processing. Partner with iMerit to get the high-quality data workflows your robot learning models need to succeed in the real world.