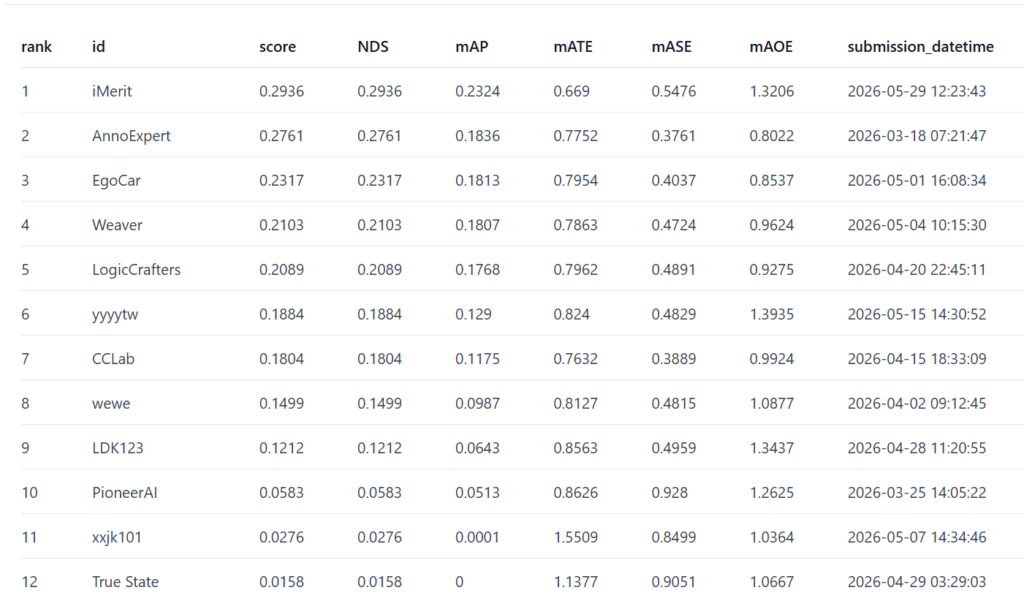
At the CVPR 2026 Auto Annotation (Auto3D) Challenge, iMerit placed first among 12 teams on the official test leaderboard. Our submission led the field in detection quality, outperforming the next-best team by +0.049 mAP, and achieved the best translation accuracy (mATE) among the top three teams.
What the challenge asked for
The Auto3D challenge is a hard, practical problem in autonomous-driving perception: produce 3D bounding boxes for a fine-grained 25-class taxonomy on the PandaSet dataset, everything from common road users like Car and Pedestrian down to long-tail classes like Pedicab, Tram, Pylons, and Rolling Containers, with no 3D training labels from the target domain. That last constraint is the whole point. Hand-labeling 3D cuboids in LiDAR is one of the most expensive, slowest steps in building an autonomous-driving dataset.
In practical terms, the challenge asks a simple question: how effective can auto-annotation be when no target-domain 3D labels are available for training? Submissions are scored by Optimized NDS, a metric that combines 3D average precision with translation, scale, and orientation error on matched objects.
Our starting point: the AutoExpert baseline
The challenge builds on the auto-annotation framework introduced by AutoExpert (Ma, Hua, and Kong, 2025), which established the modality-bridging recipe we work in: a 2D foundation model localizes objects in images, then sensor calibration and a geometric stage turn each 2D detection into a 3D cuboid, all without a 3D detector trained on the target labels.
We adopted two things from AutoExpert directly: its two-stage decomposition, 2D object detection, followed by 3D cuboid generation for each 2D detection; and its multi-hypothesis testing (MHT) cuboid fit, enumerate candidate box poses and keep the one that best explains the LiDAR points (coverage) and the image evidence (IoU with the 2D box). Beyond those core components, we re-engineered the pipeline to optimize for the challenge’s Optimized NDS metric.
The central idea remained the same: perform object understanding in 2D, where foundation models are strongest, and then lift those detections into 3D. In our pipeline we split the 3D step into an explicit lifting stage and a cuboid-fitting stage, so the walkthrough below has three stages; the section after that summarizes exactly where we diverged from the baseline.
Stage 1: Open-vocabulary 2D detection
We use SAM 3, Meta’s promptable open-vocabulary segmentation model, to detect objects in the RGB camera images, no closed-set detector trained on the 25 classes required. One of the most effective improvements came from prompt engineering: how you phrase the text prompt for each class is a first-order factor in downstream 3D accuracy.
For example, prompting SAM 3 with “bollard” for the Pylons class, “garbage bin” for Rolling Containers, “big rig” for Semi-truck, and “rickshaw” for Pedicab dramatically improved recall. Replacing raw class names with engineered prompts alone improved validation performance by +0.042 NDSopt on the validation split and nearly doubled matched true positives (52 → 88). We also added per-class score thresholds, lower for recall-starved long-tail classes, higher for high-volume classes like Car to suppress false positives.
Stage 2: Lifting 2D detections into 3D
We project the LiDAR point cloud into the image, keep the points that fall inside each detection’s mask, and cluster them. We then use a heuristic for cluster selection: for most object categories, the nearest cluster is typically the correct one (objects occlude their background), but for vehicles we take the largest cluster, because distant vehicles often contain relatively few LiDAR points and can otherwise be overwhelmed by background noise.
Extending this “biggest cluster” rule to all vehicle classes added another +0.024 NDSopt on the validation split.
Stage 3: Cuboid fitting and verified fusion
We fit each 3D box by searching over position and orientation to best explain both the LiDAR points and the 2D mask. Then we fuse in a point-cloud detector (LION-Mamba, pretrained on Argoverse-2) to sharpen orientation and size estimates. However, there’s a catch: when applied zero-shot to PandaSet, the point-cloud detector generated a significant number of false positives. So we added a lightweight CLIP-based verification head that keeps a box only if its image appearance agrees with the predicted class. This verification step transformed the detector from a noisy signal into a useful source of refinement.
Extending this “biggest cluster” rule to all vehicle classes added another +0.024 NDSopt on the validation split.
How does the refinement actually work?
We don’t let LION overwrite our boxes completely. Instead, each image-driven detection is matched to the nearest CLIP-verified LION box of the same class within a 2 m radius in bird’s-eye view, close enough to assume both refer to the same physical object. For a matched pair, we keep the box centre (cx, cy, cz) from our own cuboid fit, the SAM 3 mask plus LiDAR projection localizes position more accurately than LION on this data, and adopt the yaw and the L×W×H extent from LION, which a detector trained directly on point clouds estimates more reliably than mask-based projection.
In practice, our pipeline determines object position, while LION contributes orientation and size estimates. Image-driven detections with no LION match inside 2 m fall back to universal per-class size priors for their extent. Finally, the CLIP-verified LION boxes are also appended as independent detections, and the combined set is deduplicated with non-maximum suppression so the higher-scoring box wins on any overlap.
Finally, a small LoRA adapter on SAM 3, trained only on 2D supervision, rescued the seven rarest classes that prompts alone kept missing (Road Barriers, Construction Vehicle, Personal Mobility Device, Pedicab, Rolling Containers, Pylons, and Tram or Subway). Importantly, the fine tuning is scoped to those seven classes only: we use the LoRA-adapted SAM 3 to detect those seven categories, and the unmodified, off-the-shelf SAM 3 for every other class, so the adapter targets exactly the long tail without disturbing the classes that already work. It was the single biggest gain in the whole pipeline: +0.051 NDSopt on the validation split.
What we did differently from the baseline:
The shared skeleton is AutoExpert’s two-stage recipe: 2D detection followed by MHT-based 3D cuboid generation that scores candidates using LiDAR-point coverage and IoU against the 2D box. We kept that scoring formulation and re-engineered almost everything around it:
| Stage | AutoExpert Baseline | Our Pipeline |
|---|---|---|
| 2D detection | GroundingDINO, finetuned with multimodal few-shot adaptation and VLM-refined class prompts, plus SAM for foreground masks | SAM 3 open-vocabulary detection + segmentation, driven by per-class engineered prompts and per-class score thresholds |
| Orientation & size prior | A large VLM (GPT-4o, with Qwen as an open-source alternative) infers each object’s dimensions and visible faces, which seed the cuboid’s orientation and extent | No VLM in the loop. A CLIP-verified LION-Mamba point-cloud detector (pretrained on Argoverse-2) supplies yaw and extent |
| 2D-to-3D lifting | SAM foreground mask → MHT initialized from the VLM’s dimension/orientation, searching a narrow pose sector | SAM 3 mask → DBSCAN clustering with a class- aware selection heuristic (largest cluster for vehicles, extent sanity-check for cars) to isolate the object points |
| Rare classes | Multimodal few-shot finetuning of GroundingDINO | A LoRA adapter on SAM 3, trained on 2D supervision only, targeting the seven hardest long-tail classes |
The biggest structural difference is the orientation and size prior. AutoExpert’s v-MHT leans on a large vision-language model (GPT-4o) to infer per-object dimensions and orientation before the
MHT search; we drop that prior and instead recover yaw and extent from a CLIP-verified point- cloud detector. This is a deliberate trade-off, not a free win: our lighter pipeline leads the leaderboard on detection (mAP) and translation (mATE), but it trails the top peers on scale (mASE) and orientation (mAOE) error, precisely where a heavyweight VLM prior helps most. Because the Optimized NDS metric is dominated by the detection term, the trade still nets out in our favor overall.
We also explored two ways to recover that orientation/size accuracy at lighter weight, a ResNet-18 vehicle-direction classifier, and Qwen-VL at 3B/7B as lightweight, open-source stand-ins for a heavyweight VLM prior. Neither moved Optimized NDS on
PandaSet: the smaller VLMs were too noisy to help the MHT search, and the direction classifier’s gains evaporated on the dataset’s many tiny, distant vehicles.
The results, Decomposed
On the validation split, the full pipeline reached 0.361 Optimized NDS, up from a 0.246 naive baseline a +47% relative improvement. The improvements were distributed across all three major stages of the pipeline:
- Detection (prompts + thresholds): +0.045 NDSopt
- Lifting (class-aware clustering): +0.026 NDSopt
- Fusion (CLIP-verified priors + rare-class LoRA): +0.044 NDSopt
Along the way, detection precision (mAP3D) nearly tripled (0.097 → 0.291) and orientation error (mAOE) roughly halved (1.648 → 0.993) across our own cumulative pipeline.
Qualitative results
A few examples from the pipeline. In each pair, the left image shows the 2D detection on the camera frame and the right shows the fitted 3D box projected onto the LiDAR point cloud. Green = ground truth, red = our prediction, the closer the two boxes, the better.
Cone – a small, long-tail object recovered from a sparse cluster of LiDAR points:
2D Detection

3D Box on LiDAR

Pedestrian – a tall, thin object where orientation is ambiguous but localization stays tight:
2D Detection

3D Box on LiDAR

Car – a dense, well-sampled vehicle where the predicted cuboid closely tracks the ground-truth extent and yaw:
2D Detection

3D Box on LiDAR

This work demonstrates how far auto-annotation can be pushed without access to target-domain 3D labels. By combining open-vocabulary perception, geometry-based lifting, class-aware clustering, and lightweight verification, we built a system that achieved the top position in the CVPR 2026 Auto Annotation Challenge.
As autonomous-driving datasets continue to grow in size and complexity, reducing reliance on manual 3D labeling will become increasingly important. We are excited to contribute to that progress through practical, scalable approaches to automated annotation.
We presented this work at the CVPR 2026 Auto Annotation Challenge Workshop.