A robot can correctly identify a mug and still fail when it tries to pick it up. Recognition alone is not enough. What is missing is an understanding of how to interact with the object. Most robotics datasets focus on perception tasks like object detection and segmentation. But dexterous robotics requires robots to understand object states, affordances, contact regions, and how interactions change over time.
This is where object-level labels become important. They help bridge the gap between seeing an object and understanding how to manipulate it safely and effectively. As embodied AI and multimodal robotics systems advance, interaction-centric data is becoming essential for building reliable robotic systems.

In this article, we explore what object-level labels are, why most manipulation training datasets still lack them, and how they improve robotic grasping and manipulation learning.
What Are Object-Level Labels?
Object-level labels in manipulation datasets go past detection. They capture an object’s condition, how it’s handled, and what happens on contact.
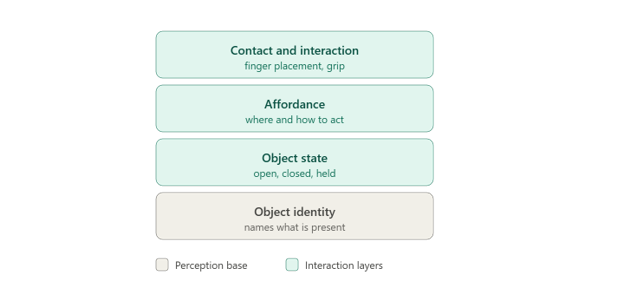
Object Identity Labels
Identity labels name what sits in the scene. A mug, a drill, a cardboard box, and a drawer handle each get a class tag. This is the same work that powers standard object detection, and it forms the base layer everything else builds on.
Object State Labels
State labels say what condition an object is in at any moment. A drawer is open or closed, a cloth is folded or loose, a part is held or set down. None of this stays fixed for long.
Each time the robot acts, the state can shift, and the label has to keep up. State is how a system knows if a step worked. When a gripper closes on nothing, the object stays put, and the data should show the grab failed.
Affordance Labels
Affordance labels mark how an object can be acted on, not just where it sits. A handle invites a grip, a flat top offers a support surface, and a slot accepts a peg. These labels flag the regions that matter for a given action, which helps robots handle objects they’ve never seen.
Researchers treat affordances as a compact intermediate representation. In the RT-Affordance paper, the authors showed that conditioning manipulation policies on affordances improves generalization to new objects and scenes. The benefit is reuse, not relearning every object from scratch.
Contact and Interaction Labels
Contact labels zoom in on the moment a hand meets an object. They record where the fingers land, how the grip lines up, and which surface takes the load. This is the finest-grained layer in dexterous manipulation, and it shapes whether a grasp holds or slips.
Some recent systems depend on it directly. The A0 model was pre-trained on a large set of contact points, then fine-tuned across several robot platforms.
Detection can skip these details, but manipulation cannot.
Why Most Manipulation Training Datasets Skip the Interaction Layer
Most robotics datasets weren’t built for manipulation. They came out of computer vision (CV), where the goal was perception, not physical interaction.
Static Perception Bias
Classic vision datasets are built around single frames. Draw a box, label a mask, move on. That setup is great for detection and segmentation, but it says nothing about what happens when a robot touches something.
Real interaction data is harder to build. The team behind DROID notes that most manipulation policies are still trained in a few settings with limited task variety, because building diverse interaction data takes hardware, time, and labor.
Temporal Annotation Challenges
Manipulation plays out over time, so the labels must too. An object that’s clear in one frame can rotate, get occluded, or slip out of view, and the label still has to follow it. That sequence-level consistency is hard to produce.
Taxonomy Complexity
Then there’s the problem of definitions. Affordances, object states, and interaction labels all need consistent rules, and those rules get slippery at scale.
A graspable region on one tool can look nothing like the same region on the next. With hundreds of annotators and thousands of objects, those small disagreements stack up fast.
Human Expertise Requirements
Accurate contact and interaction annotations require expert judgment. Reviewers need to understand how a gripper engages with an object and whether the labeled grasp would remain stable during execution. Small annotation errors can significantly affect manipulation performance.
iMerit combines domain experts in robotic manipulation with structured quality control workflows, helping ensure contact and grasp annotations are accurate before they reach model training.
Why Object-Level Labels Matter for Dexterous Robotics
Object-level labels pay off across four areas, including handling objects, adapting to new ones, running multi-step tasks, and connecting sight to action.
Better Robotic Grasping
A grasp fails when the robot closes on the wrong spot. Object-level labels work against that on several fronts. Contact labels mark where the fingers land, affordance labels flag the regions that hold, and state labels show whether the grip took or slipped.
Take a mug as an example. An affordance label flags the handle as the place to grip. A contact label marks where the fingers land on it. A state label then confirms whether the robot grabbed the mug or missed.
Improved Generalization
Memorizing every object doesn’t scale. Object-level labels let a robot learn concepts it can reuse instead of relying on a fixed list of objects. These concepts include affordances such as parts designed for grasping, states such as open or closed, and contact regions that remain stable across similar shapes.
Take a drawer the robot has never seen. An affordance label for graspable parts still points to the handle. A state label for open or closed still tells it whether the drawer is shut. A contact region works the same way. Label the gripping region on ten kinds of mugs and the eleventh stops being a problem.
Long-Horizon Manipulation Tasks
Some tasks run over many steps, and finishing them means remembering what’s already done. Identity and state labels give the robot that memory. In a bin-sorting task, identity labels keep each part distinct while state labels track which ones are already sorted, so the robot always knows what’s left. Keeping that identity consistent from frame to frame is the backbone of video annotation for machine learning.
Without it, a model seeing only the current frame can’t tell a finished step from a new one. That’s the breakdown the team behind LoLA traced over a long sequence.
Stronger Embodied AI Systems
Dexterous robotics is where embodied AI gets tested, and it needs more than appearance. Object-level labels describe an object by what can be done with it, the signal a system needs to act on it, not just recognize it. Train on appearance alone, and the model can name a scene but can’t handle what’s in it.
A 2025 review of embodied intelligence for manipulation surveys how interaction-centric learning connects perception to physical action.
Annotation Challenges in Dexterous Robotics
Building manipulation datasets is hard work, and the same handful of problems surface on almost every project.
Multi-Modal Synchronization
Manipulation data rarely comes from one sensor. It spans video, depth, tactile, and force readings along with hand and object pose, and a recent dexterous-hand dataset. HRDexDB brings several of these streams together for a single grasp. A usable label needs all of them aligned in time and space.
The main modalities a manipulation dataset has to reconcile, and why each is hard to line up:
| Modality | What It Captures | Why is It Hard to Align |
|---|---|---|
| RGB video | Appearance, object identity, scene layout | Multiple camera views must share calibration and timestamps |
| Multiple camera views must share calibration and timestamps | 3D geometry and distance to surfaces | Often lower resolution and frame rate than the paired RGB stream |
| Tactile | Contact and pressure at the fingertips | Sampled far faster than video, so it has to be resampled and time-matched |
| Force and torque | Load at the wrist or joints | Tied to the robot's action, not the camera, so frames must be matched |
| Hand and object pose | 3D hand joints and 6D object position | Separate coordinate frames must be registered together |
Timing is the hard part. A tactile spike has to sit on the exact frame the finger lands, and if it drifts by even one frame, the label stitches two separate moments into one.
Edge Case Complexity
Some scenes defeat the tools before annotation begins. Glass and polished metal scatter depth readings, so the geometry that an annotator depends on comes back wrong.
Clutter hides parts of an object, and soft things like cloth or cable shift shape as they move. With no stable outline to trace, the label is a guess, and the robot inherits it.
Evaluating Object-Level Labels in Manipulation Systems
Because manipulation labels encode interactions, they require evaluation methods beyond traditional perception metrics.
Once object-level labels in manipulation datasets exist, teams have to check whether they make a robot more reliable. What the check reveals depends on the level it targets.
Frame-Level vs Interaction-Level Evaluation
The first level is frame-level perception, and it flatters almost everything. Detection looks sharp, the masks line up, and the scores come back high. On a static benchmark, a model can look close to solved.
Those scores go quiet the moment the robot moves. The team behind RoboEval found that binary success metrics often hide poor coordination and slipping during a grip, the kind of failure that shows up only once the interaction is underway.
Grasp Success Metrics
Watching the grip itself is the next level down, and it picks up what perception scores drop. The signals worth tracking are whether the hold stays stable, whether the object slips, and whether the task finishes.
Sequence-Level Benchmarking
Length is the level most short tests skip. A clean five-second demo barely hints at how a robot handles eight steps and the handoffs between them.
Stretch the task out and the buried failures climb into view. State errors stack across steps, one early slip skews everything after it, and the run comes apart in ways a quick clip would never catch. The longer the task, the more places a small error has to turn into a failed run.
Human Evaluation in Robotics Systems
The last level is the one no metric reaches. A motion can clear every automated threshold and still look wrong to a person watching it back.
Reviewers catch the awkward re-grip, the shaky approach, the grasp that scored as a success but would fold in a real kitchen or warehouse.
What Does Production-Ready Manipulation Require?
A robot that works in a demo still has to hold up on a real floor, which is why production systems lean on monitoring, error limits, and people in the loop.
Monitoring Manipulation Failures
In deployment, the failures are physical and specific. Teams watch for grips that wobble, dropped objects, and stalled steps.
Scale is what makes this matter. In an eleven-month BMW plant pilot, two of Figure’s robots moved over 90,000 components in roughly 1,250 hours. At that volume, even a hypothetical 1 percent error rate would mean 900 mishandled parts to catch and log.
Defining Interaction Thresholds
Not every task tolerates the same error. A robot stacking soft boxes can afford a rougher grip than one placing a fragile part on a lince.
So thresholds get set per application. Each deployment decides how much slip or misplacement counts as a failure, and what to do when it does: retry, stop, or hand off.
Integrating Evaluation and Annotation
Production data feeds straight back into the labels. Every logged failure shows where the model struggles, worth annotating and folding into the next training round.
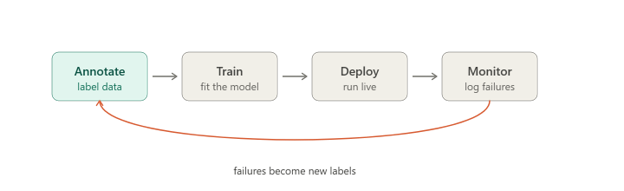
Run that loop, and the system keeps improving in the field. It only works, though, if evaluation and annotation stay connected rather than sitting in separate pipelines.
Human Oversight in Robotics Operations
People still cover what the robot can’t. In warehouse settings, humans handle the exceptions while robots run the repetitive work.
That oversight is also a data source. Much like human feedback shapes a model’s behavior in RLHF, a reviewer stepping in on an edge case fixes it and records how it should have gone.
How iMerit Supports Object-Level Labeling for Dexterous Robotics
Reliable manipulation depends on structured interaction data and evaluation that scales. This is the work iMerit is built for.
Advanced Robotics Data Annotation
iMerit runs the annotation workflows behind object-level labels, from affordance labeling to object state tracking and frame-to-frame temporal links. This robotics data annotation turns raw footage into interaction-focused manipulation datasets that a robot can actually learn from, not just perception data. The harder cases get the same care, occlusion, reflective surfaces, deformable items, and multi-sensor streams that have to stay aligned.
Sequence-Level Robotics Evaluation
Beyond labeling, iMerit’s data solutions extend to evaluation. The focus sits on robotic grasping reliability, manipulation continuity, and how a policy holds up across long multi-step tasks rather than single clean frames. Testing runs on full sequences, where slips and state errors actually surface.
Human-in-the-Loop Robotics Operations
Expert reviewers anchor the full pipeline. They handle quality assurance, surface the edge cases that automated checks miss, and feed corrections back in. That last step is the loop that keeps production robotics systems improving once they leave the lab and meet real conditions.
Conclusion
Object detection alone is no longer enough. Robots also need to know how objects behave and how interactions change over time. Object-level labels in manipulation datasets provide that missing layer, and the teams that build it early tend to ship systems that hold up outside the lab.
Key Takeaways
- Object-level labels capture identity, state, affordances, and contact that the layer detection misses
- They improve grasping, generalization, and long multi-step tasks
- State and identity labels let a robot track progress across a sequence
- Expert review and full-sequence evaluation are what make a dataset reliable
iMerit’s robotics annotation, powered by Ango Hub and domain-expert annotators, builds high-quality object-level datasets for robotic manipulation, embodied AI, and production robotics. Talk to an iMerit expert to get started.