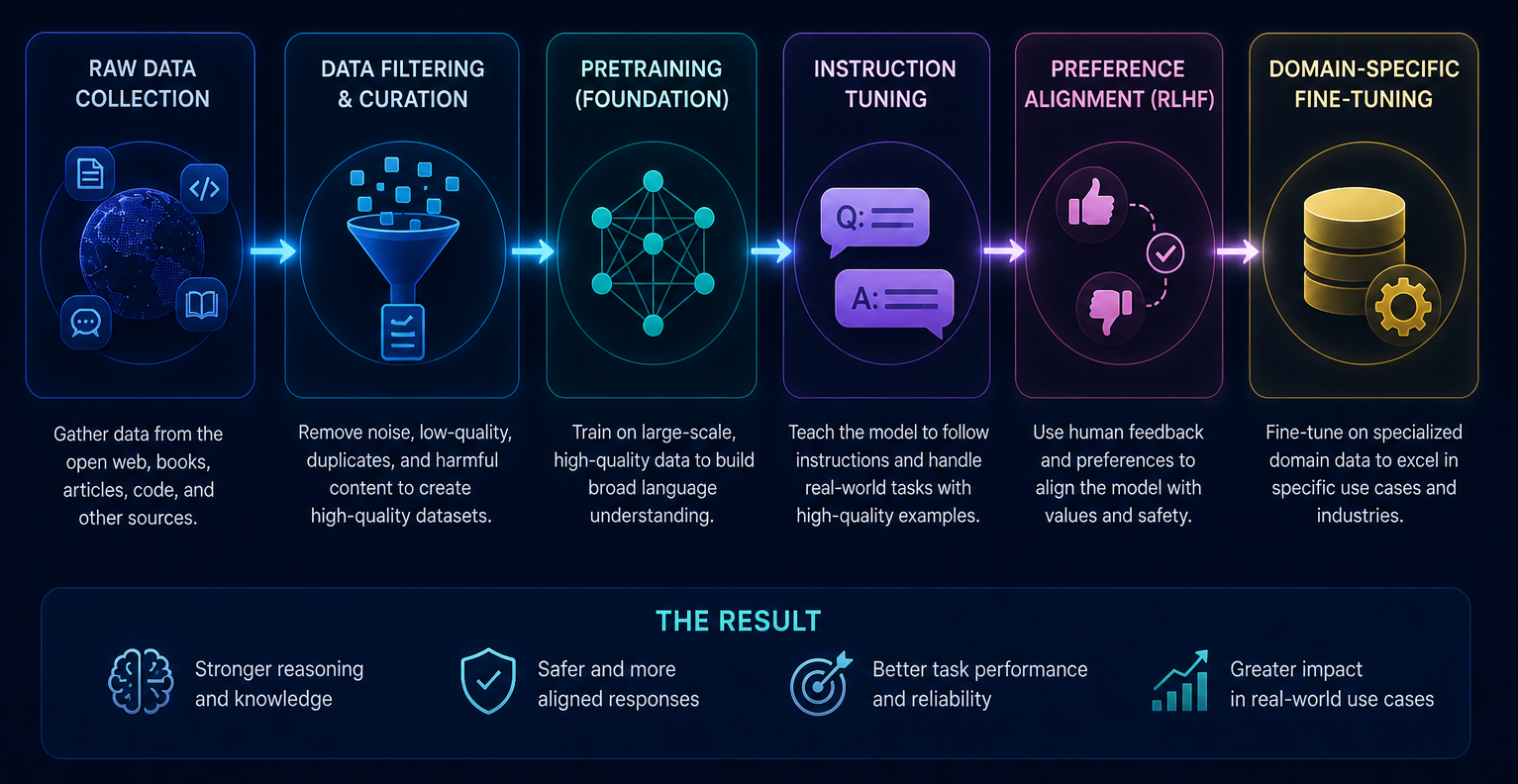
Large language models depend on extensive, high-quality training data. Whether you’re building a general-purpose chatbot, a coding copilot, a medical AI assistant, or a domain-specific reasoning model, choosing the right dataset saves months of work and produces models that genuinely perform in production. Here are the leading LLM training datasets for 2026, covering web-scale corpora, instruction tuning, code generation, alignment, and conversational AI.

1. MIMIC-IV Clinical Notes
Size: Millions of de-identified clinical records | License: Credentialed access | Use case: Clinical NLP, healthcare LLMs, and medical reasoning models
MIMIC-IV is one of the most widely used healthcare language datasets for medical AI research and domain-specific LLM development. Developed by MIT and Beth Israel Deaconess Medical Center, it contains de-identified physician notes, discharge summaries, radiology reports, and ICU records collected from real clinical environments. The dataset is extensively used for clinical reasoning, medical summarization, question answering, and healthcare-focused conversational AI. For teams building medical LLMs, MIMIC-IV provides highly specialized healthcare language and terminology that general-purpose web datasets cannot replicate.
2. Common Crawl
Size: 345 TiB (March 2026 crawl) | License: CC0 (public domain) | Use case: Large-scale web text pretraining for foundation LLMs
Common Crawl is the bedrock of modern LLM pretraining. Its monthly web archive spans hundreds of terabytes of text across nearly 2 billion pages. Because it’s public domain, it’s the raw material from which dozens of derivative datasets; C4, OSCAR, RefinedWeb, are built. Virtually every major language model has Common Crawl in its training lineage. Teams almost always apply quality filtering pipelines before use, but its scale and zero licensing cost make it indispensable as a pretraining base.
3. FineWeb (Hugging Face)
Size: 15 trillion tokens | License: ODC-By | Use case: High-quality educational and web-text pretraining for reasoning-focused LLMs
FineWeb is Hugging Face’s 2024 release and arguably the most important new pretraining dataset in recent years. Built from 96 Common Crawl snapshots with aggressive quality filtering, it outperforms every other open web dataset on standard LLM benchmarks. The FineWeb-Edu subset filtered specifically for educational content is particularly powerful for building models with strong reasoning and knowledge capabilities. It represents the current state of the art in open web pretraining data.
4. The Stack v2 (BigCode)
Size: 67.5 TB source code | License: Apache 2.0 | Use case: AI coding copilots, code completion, and software engineering assistants
The Stack v2 is the largest open code dataset available, covering permissively licensed source code across 600+ programming languages. It powers the StarCoder2 family of models and is the standard pretraining corpus for code-generation LLMs in 2026. For teams building software engineering AI copilots, automated testing, code review tools The Stack v2 provides the language and paradigm coverage that no competing open dataset matches.
5. Dolma (Allen AI)
Size: 3 trillion tokens | License: ODC-By | Use case: Transparent multi-source pretraining for auditable enterprise LLMs
Dolma is the training corpus behind AI2’s OLMo models and one of the most transparently documented large-scale datasets available. It combines web text, scientific papers, code, Wikipedia, books, and social media with every data source, filtering decision, and processing step fully documented. For teams that need both scale and auditability, Dolma is the most responsibly built pretraining corpus available today.
6. RedPajama-Data v2
Size: 100B+ tokens | License: Apache 2.0 | Use case: Commercial-friendly pretraining for open-source foundation models
RedPajama-Data v2 is an open replication of Meta’s LLaMA training set, providing over 100 billion tokens of filtered, deduplicated web text. Its Apache 2.0 license allows full commercial use, a meaningful distinction from research-only datasets. The v2 release includes quality signals and deduplication metadata, giving teams flexibility to apply their own filtering strategies rather than relying on a fixed pipeline.
7. FLAN v2 (Google)
Size: Multi-task collection | License: CC BY 4.0 | Use case: Multi-task instruction tuning for conversational AI assistants
FLAN v2 aggregates thousands of NLP tasks including classification, summarization, translation, Q&A, reasoning all reformatted as natural language prompts and responses. It was used to fine-tune Google’s Flan-T5 and Flan-PaLM models, producing dramatically stronger zero-shot and few-shot generalization. For teams building task-agnostic AI assistants, FLAN v2 remains one of the most reliable instruction-tuning foundations available.
8. OpenHermes 2.5
Size: 1 million instructions | License: Apache 2.0 | Use case: Chatbot fine-tuning for reasoning, coding, and conversational AI
OpenHermes 2.5 is a curated synthetic instruction dataset generated primarily using GPT-4, covering coding, reasoning, math, and general conversation. It’s one of the highest-quality open instruction-tuning datasets available and has been used to produce models that punch significantly above their parameter count. For teams fine-tuning smaller models to behave like much larger ones, OpenHermes 2.5 is a go-to resource in 2026.
9. The Pile (EleutherAI)
Size: 825 GB | License: MIT | Use case: Multi-domain language modeling across research, legal, coding, and creative text
The Pile combines 22 diverse, high-quality sources books, academic papers, GitHub, legal documents, and curated web text into a single 825 GB corpus. Though newer datasets have surpassed it in scale, The Pile’s diversity and domain coverage still make it valuable for training models that need strong performance across academic, professional, and creative tasks. Its MIT license also makes it one of the most permissively licensed large-scale corpora available.
10. UltraFeedback
Size: 64,000 instructions | License: MIT | Use case: Alignment tuning for more helpful, safer, and instruction-following AI assistants
UltraFeedback is a large-scale preference dataset where instructions were sent to multiple LLMs and the outputs were scored by GPT-4 for quality, helpfulness, honesty, and instruction-following. It’s the primary dataset behind several leading open RLHF-tuned models in 2026, including Zephyr and Mistral-based fine-tunes. As reinforcement learning from human feedback becomes standard practice for production LLMs, UltraFeedback provides the preference signal that makes models noticeably more aligned and helpful.
Conclusion: Build Better AI With the Right LLM Training Datasets
These 10 LLM training datasets span the full foundation-model pipeline, from large-scale web pretraining and code generation to instruction tuning and alignment. As enterprise AI systems continue to evolve, high-quality and well-filtered datasets remain one of the biggest factors influencing reasoning capability, reliability, and real-world model performance.