Healthcare is experiencing a data-driven revolution. From AI models reading radiology scans to predictive algorithms guiding clinical workflows, medical data is reshaping healthcare. But there is a catch: much of that data contains personally identifiable information (PII) or protected health information (PHI). Without robust safeguards, patient privacy is at risk, and with it, compliance with laws like HIPAA in the U.S. or GDPR in Europe.
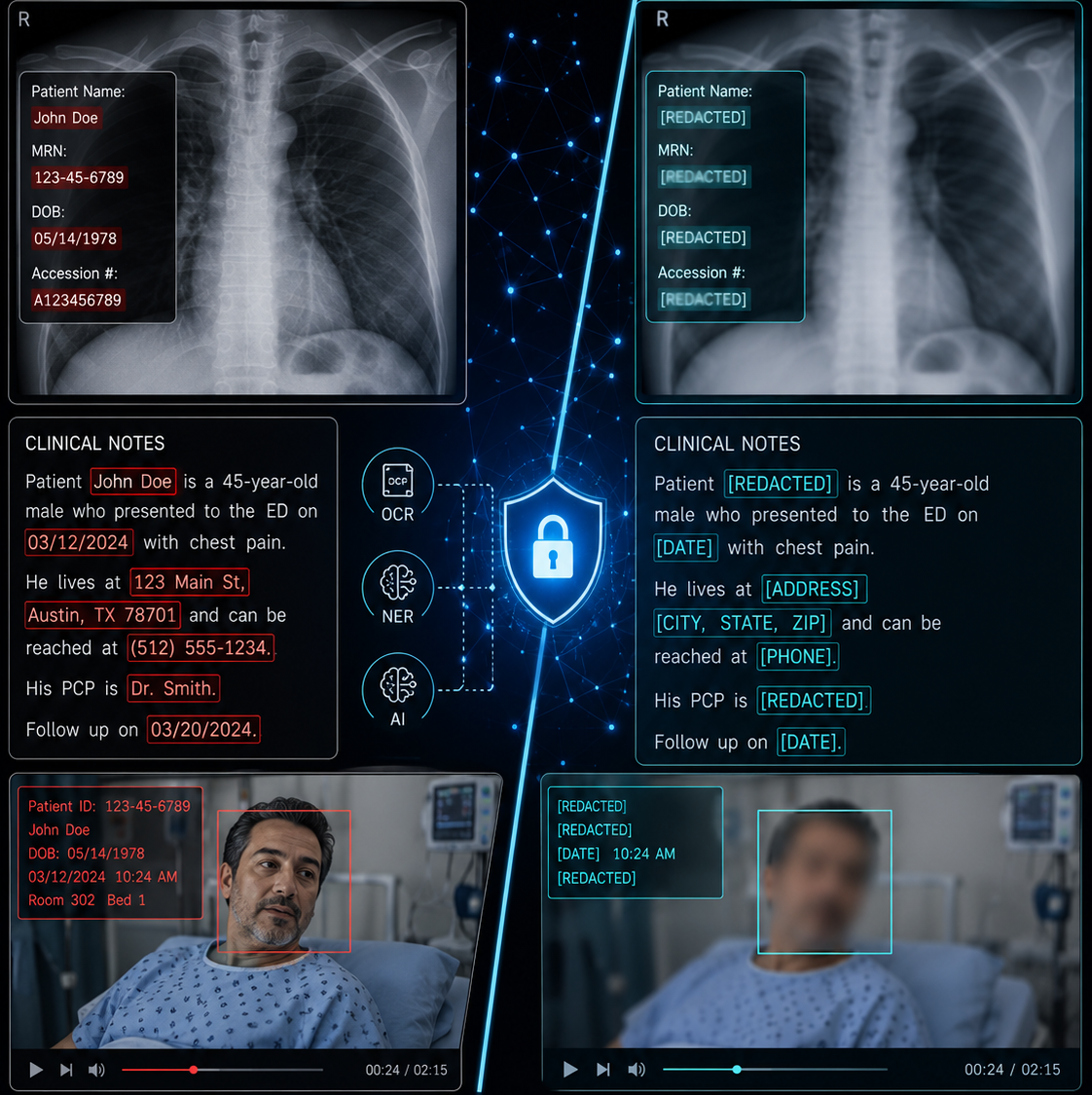
That is where de-identification comes in. Stripping sensitive details before medical data labeling allows researchers, clinicians, and AI developers to unlock its value while minimizing privacy risks. Yet, doing this at scale, and doing it well, is no easy task.
The Challenges of De-Identification
One of the biggest hurdles is the privacy versus utility trade-off. Every time an identifier is removed, there is a chance that the data loses some of its clinical richness. For example, redacting dates may protect privacy but also eliminate useful insights about disease progression. Striking a balance is critical. Too much protection, and the data becomes useless. Too little, and patient identities remain vulnerable.
Another challenge is the mosaic effect. Even when obvious identifiers are stripped, seemingly harmless fragments of information can be pieced together across datasets to re-identify individuals. A postal code combined with a birth year, for instance, might be enough to pinpoint someone in a smaller population.
There is also the complexity of data formats. Structured datasets, like EHR tables, may contain hidden quasi-identifiers. Free-text clinical notes are filled with context-sensitive PHI that machines often miss. Medical imaging and video introduce a different challenge: metadata and even visual elements can reveal identities if not handled carefully.
Finally, evolving threats make the task harder. Techniques like membership inference attacks, where an adversary can guess whether someone’s data is part of a dataset, remind us that de-identification is not a one-time process but an ongoing arms race.
Emerging Solutions and Technologies
Despite these challenges, the field is advancing quickly. Traditional methods like masking, generalization, and suppression are still widely used, but they are now being combined with more sophisticated tools.
- Differential privacy introduces controlled noise, allowing researchers to analyze trends without exposing individuals.
- Synthetic datasets are gaining momentum, creating simulated patient records that mimic real-world data distributions without tying back to real people.
- Federated learning enables AI models to train across distributed datasets without ever moving the raw data, reducing exposure risks.
AI is also stepping up in powerful ways. Natural language processing models, including transformers like BERT, are improving at spotting PHI in free text. Open-source frameworks are being fine-tuned for clinical notes, imaging metadata, and even pixel-level analysis. On the imaging side, hybrid approaches that combine OCR, named-entity recognition, and human review are making it possible to scale de-identification while maintaining accuracy.
Cutting-edge research is also testing bold new approaches. For example, DeID-GPT uses large language models for zero-shot text de-identification. In medical video, deepfake-style anonymization can replace patient faces while preserving diagnostic features, offering privacy without undermining downstream AI tasks.
Building a Multi-Layered Strategy
What is becoming clear is that there is no single silver bullet. Effective de-identification strategies are layered. They start with a careful risk assessment and regulatory framework, such as Safe Harbor or Expert Determination under HIPAA. They combine methods: masking where it is safe, pseudonymization where traceability is needed, synthetic data where real data poses too much risk.
Automation plays a critical role, but human-in-the-loop review remains essential. Domain experts provide oversight when algorithms face ambiguity, ensuring that data protection does not come at the cost of clinical meaning. And, perhaps most importantly, every step needs to be auditable and explainable to maintain trust with regulators and healthcare institutions.
Looking Ahead
The demand for AI-ready healthcare data is only going to grow. At the same time, patients, regulators, and clinicians are rightly demanding stronger privacy protections. That tension will continue to drive innovation in de-identification, blending classic statistical methods with AI-powered detection, and pairing automation with human judgment.
Where iMerit Fits In
When it’s time to take de-identification from theory to practice, organizations often need a partner that bridges research innovation with real-world deployment. iMerit does exactly that, offering both services and custom engineering solutions:
De-identification Services
- OCR and Entity Tools via Ango Hub
iMerit’s Ango Hub platform includes OCR capabilities to detect, transcribe, and localize text within images; as well as NER and entity extraction for structured and unstructured text.
- Automated PHI Detection with Expert Oversight
Pre‑trained NLP models identify HIPAA’s 18 protected health identifiers and obscure them automatically, with optional human‑in‑the‑loop review to ensure quality and compliance. - HIPAA Compliance and Visual Redaction
The solution securely blurs or obscures sensitive content (photos, burned‑in text, metadata) without compromising data integrity or model utility. - Seamless Integration and Workflow Support
File‑explorer plugins and platform workflows simplify importing, exporting, monitoring, and project analytics on the Ango Hub, streamlining de‑identification pipelines. - Scalable Hybrid‑Workforce Model
A global team of domain‑trained experts, including US board‑certified physicians, ensures scalable, high‑quality de‑identification with strong auditability and regulatory alignment.
Custom Model Engineering
- End-to-End Model Development
Build de-identification models tailored to client datasets across text, imaging, and video. - Dataset Creation & Training
Curate secure datasets to train or fine-tune PHI detection models. - Deployment & Integration
Support for on-prem or cloud environments with compliance-grade traceability. - Human-in-the-Loop Oversight
Continuous expert validation of model outputs to maintain accuracy and compliance post-deployment. - Ongoing Optimization
Iterative retraining and refinement as new data types or regulatory requirements emerge.
For healthcare organizations and AI teams, partnering with iMerit means your data can be safely de-identified through flexible service workflows, fully custom-built models or both, while retaining clinical value, regulatory alignment, scalability, and trust.
Want to learn more?
Contact us to explore how iMerit can accelerate your medical data de-identification initiatives with data you can trust.
Schedule a Demo or Talk to Our Experts Or Explore Our Medical Data De-Identification Solutions.